GROUP BY in SQL
The subject of “GROUP BY” in SQL statements has come up a couple of times at Box UK lately, and I notice that extensions to MySQL often give people a slightly inaccurate impression of what it does. Or rather, what it can be relied on to do. So I thought I’d try and clear up some of the key points in this blog post.
Aggregating values
In theory at least, GROUP BY is for aggregating values from rows in a table. It’s not intended for selecting out individual rows.If you have a table like this:
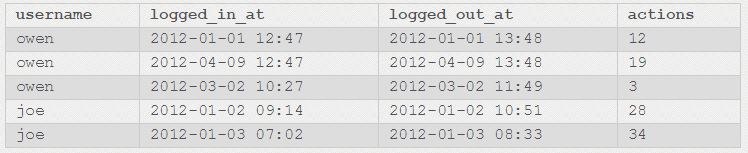
And you run this:
SELECT username, count(*)
FROM session_history
GROUP BY username
You get:
owen 3
joe 2
You could also do:
SELECT username, MIN(logged_in_at)
FROM session_history
GROUP BY username
owen 2012-01-01 12:47
joe 2012-01-02 09:14
Or:
SELECT username, MIN(actions), MAX(actions), AVG(actions)
FROM session_history
GROUP BY username
owen 3 19 11.33
joe 28 34 31
Handling non-aggregates
That’s pretty straightforward. And of course you can group by multiple columns too. But what you can’t do (in standard SQL) is:
SELECT username, logged_in_at, actions
FROM session_history
GROUP BY username
(Note logged_in_at and actions aren’t listed in the GROUP BY line.)
Since the GROUP BY statement is supposed to be about aggregates, it doesn’t make sense to pull out a non-aggregated column. Which one would it use? So SQL doesn’t allow it…
… except for MySQL, which extends GROUP BY to allow that very case. The results might be:
owen 2012-01-01 12:47 12
joe 2012-01-02 09:14 28
Or they might be:
owen 2012-03-02 10:27 3
joe 2012-01-03 07:02 34
…or any other combination. The non-aggregate columns will all come from the same row (per group), but which row is indeterminate. This feature is intended for convenience when the rows in a group all have the same values for these columns, so it doesn’t matter which one is returned. Note the key point: the row returned is not specified. The server could always choose the first, the last, the middle or a random one each time. And the approach taken could change between MySQL releases.
(Actually, it’s slightly worse than that: the values aren’t even guaranteed to come from the same row!)
Controlling row selection
However, people have noticed that MySQL isn’t in fact random in its choice of row: it currently takes the first match. Which means you can do workarounds like this:
SELECT username, logged_in_at, action
FROM (SELECT * FROM session_history ORDER BY actions) as hack
GROUP BY username
owen 2012-03-02 10:27 3
joe 2012-01-02 09:14 28
(This particular sub-select ensures the row used for non-aggregate columns is the one with the smallest action.)This is very convenient. But it relies on a quirk of the current implementation. At any point they could release an update which performs a different optimisation and messes up every place this workaround has been used.
Not just a theoretical problem
Yes, this may seem pretty unlikely. But it happened with Oracle when they moved from version 9 to 10: a change in the internals meant a change to the ordering from GROUP BY and lots of people were affected.
So, should you make use of this feature in production code? That’s a ultimately a decision for you to make yourself; there are generally alternatives to using this technique (see below for a couple of examples), and I’ve yet to see an instance that couldn’t be re-written in standard SQL terms, but I concede that they aren’t always as easy to read as the MySQL extension. However, having been one of those affected by the Oracle GROUP BY change, I personally don’t want to get bitten by that problem again!